

Introduction
Unicode est une norme universelle de codage des caractères qui vise à unifier l’ensemble des systèmes d’écriture du monde en attribuant à chaque caractère un code unique. Cette standardisation facilite l’échange, le traitement et l’affichage de textes multilingues sur divers supports numériques. Avant l’introduction de Unicode, la coexistence de multiples systèmes de codage incompatibles rendait complexe la gestion des textes dans différentes langues. Unicode apporte une solution en fournissant un cadre cohérent pour représenter tous les caractères, symboles et émojis utilisés dans le monde entier.
Comment a été créé Unicode ?
L’idée de créer un système de codage universel est née à la fin des années 1980. À cette époque, les informaticiens Joe Becker de Xerox, ainsi que Lee Collins et Mark Davis d’Apple, ont entrepris de développer une norme capable de remplacer les nombreux systèmes de codage existants, souvent incompatibles entre eux. En 1988, Joe Becker a publié un document intitulé « Unicode 88 », dans lequel il exposait les principes d’un codage universel utilisant 16 bits pour représenter chaque caractère, permettant ainsi de coder jusqu’à 65 536 caractères.
En janvier 1991, le Consortium Unicode a été officiellement fondé en Californie en tant qu’organisation à but non lucratif. Son objectif principal était de développer, maintenir et promouvoir l’utilisation de cette norme. Le consortium regroupe encore aujourd’hui des entreprises majeures du secteur technologique comme Adobe, Apple, Google, IBM, Microsoft et d’autres.
Logo officiel Unicode. Source : https://en.m.wikipedia.org/wiki/File:New_Unicode_logo.svg
Comment Unicode a-t-il évolué ?
Depuis sa première publication, Unicode a connu de nombreuses mises à jour. Voici quelques jalons importants :
- Version 1.0 (1991) : introduction de la norme avec un espace de codage de 16 bits, couvrant principalement les systèmes d’écriture modernes.
- Version 2.0 (1996) : extension de l’espace de codage grâce aux paires de substitution (« surrogate pairs »), ce qui permet de représenter plus d’un million de caractères.
- Versions suivantes : ajout progressif de caractères historiques, de symboles, d’émojis, et de nouveaux alphabets pour répondre aux besoins toujours plus variés des utilisateurs.
Comment Unicode est-il organisé ?
Unicode est divisé en 17 « plans », chacun contenant 65 536 points de code (ou codes uniques de caractères), soit un total de plus d’un million de positions possibles. Ces plans sont eux-mêmes regroupés en blocs selon le type ou l’origine des caractères.
- Plan Multilingue de Base (BMP) : C’est le plus important et le plus utilisé. Il va de U+0000 à U+FFFF et contient les caractères les plus courants (latin, cyrillique, arabe, grec, chinois, japonais, coréen, etc.).
- Plans supplémentaires : Utilisés pour des caractères historiques, des langues rares, des émojis, des symboles mathématiques ou encore des zones privées pour les entreprises ou logiciels qui ont besoin de caractères personnalisés.
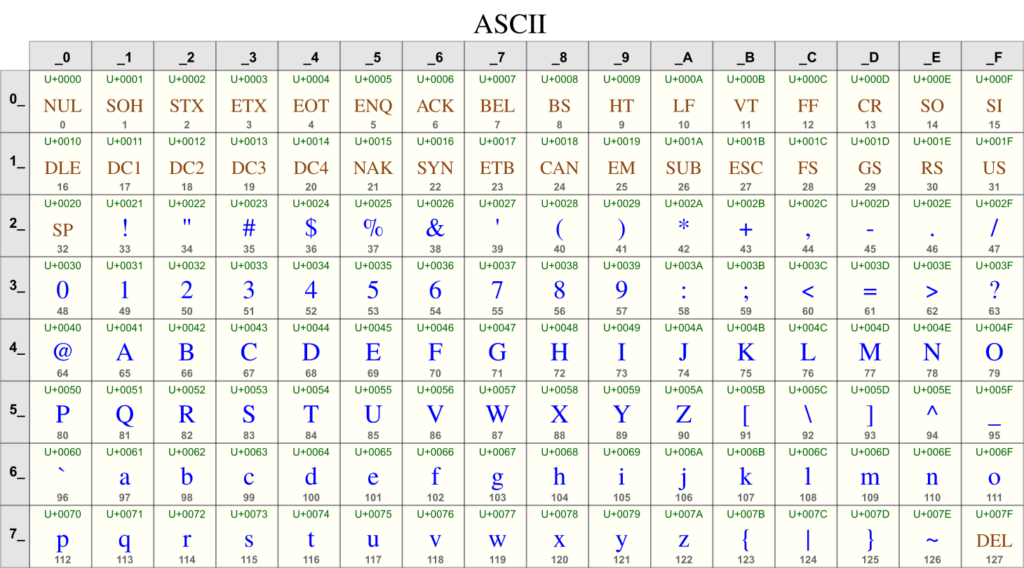
Chaque caractère a un point de code sous la forme U+XXXX (en hexadécimal). Pour stocker ces caractères, on utilise différentes formes d’encodage appelées UTF.
Quelles sont les différentes façons d’utiliser Unicode ?
Exemple de conversion Unicode. Source : https://www.bytesroute.com/blog/unicode.html
Les encodages Unicode les plus connus sont les suivants :
- UTF-8 : C’est le plus répandu, surtout sur Internet. Il utilise de 1 à 4 octets pour coder un caractère. Il a l’avantage d’être compatible avec l’ancien codage ASCII, ce qui facilite les migrations.
- UTF-16 : Utilisé notamment par Windows, il code les caractères en 2 ou 4 octets. Il est plus efficace pour les langues asiatiques qui utilisent beaucoup de caractères.
- UTF-32 : Ici, chaque caractère utilise 4 octets. C’est très simple à utiliser pour les ordinateurs, mais ça prend plus de place en mémoire.
Pourquoi Unicode est-il si important aujourd’hui ?
Avant Unicode, chaque langue avait son propre système de codage, ce qui causait de nombreux problèmes de compatibilité entre logiciels, sites web ou documents. Unicode a permis d’unifier tout ça.
Aujourd’hui, Unicode est absolument essentiel pour :
- Afficher des textes dans toutes les langues sur un même appareil ou site web.
- Envoyer des émojis ou des caractères spéciaux sans erreurs.
- Programmer des applications qui marchent partout dans le monde.
Pratiquement tous les systèmes d’exploitation modernes (Windows, macOS, Android, iOS), les navigateurs web et les langages de programmation supportent Unicode nativement.
Quels sont les défis d’Unicode ?
Unicode est très puissant, mais il doit encore faire face à plusieurs défis :
- Il faut constamment ajouter de nouveaux caractères, émojis ou scripts anciens.
- Il existe parfois plusieurs façons de représenter le même caractère (comme les accents), ce qui peut poser des problèmes lors des comparaisons de textes.
- La gestion de certains alphabets complexes demande des règles d’affichage très techniques.
Le Consortium Unicode continue de travailler pour améliorer et faire évoluer la norme en fonction des besoins du monde numérique.
Pour résumer : à quoi sert Unicode ?
Unicode permet de tout simplement écrire, afficher et transmettre du texte de manière universelle, quelle que soit la langue ou la plateforme. C’est grâce à Unicode qu’on peut lire un tweet en japonais, échanger des mails avec des accents, programmer un site multilingue ou insérer un émoji dans un message.
Unicode, c’est le langage commun de tous les textes numériques.
Sources :
- https://en.wikipedia.org/wiki/Unicode
- https://home.unicode.org/
- https://unicode.org/faq/
- https://developer.mozilla.org/en-US/docs/Glossary/Unicode
- https://www.unicode.org/standard/WhatIsUnicode.html
- https://www.joelonsoftware.com/2003/10/08/the-absolute-minimum-every-software-developer-absolutely-positively-must-know-about-unicode-and-character-sets-no-excuses/