

Introduction
Unicode is a universal character encoding standard that aims to unify all the world’s writing systems by assigning each character a unique code. This standardization facilitates the exchange, processing, and display of multilingual texts across various digital media. Before the introduction of Unicode, the coexistence of multiple incompatible encoding systems made managing texts in different languages complex. Unicode provides a solution by offering a consistent framework to represent all characters, symbols, and emojis used worldwide.
How was Unicode created?
The idea of creating a universal encoding system emerged in the late 1980s. At that time, Joe Becker from Xerox, along with Lee Collins and Mark Davis from Apple, set out to develop a standard capable of replacing the many existing, often incompatible, encoding systems. In 1988, Joe Becker published a document entitled “Unicode 88,” in which he outlined the principles of a universal encoding using 16 bits to represent each character, thus allowing up to 65,536 characters to be encoded.
In January 1991, the Unicode Consortium was officially founded in California as a non-profit organization. Its main goal was to develop, maintain, and promote the use of this standard. The consortium still brings together major technology companies such as Adobe, Apple, Google, IBM, Microsoft, and others.
Official Unicode logo. Source: https://en.m.wikipedia.org/wiki/File:New_Unicode_logo.svg
How has Unicode evolved?
Since its first publication, Unicode has undergone many updates. Here are some important milestones:
- Version 1.0 (1991): introduction of the standard with a 16-bit coding space, mainly covering modern writing systems.
- Version 2.0 (1996): expansion of the coding space thanks to “surrogate pairs,” allowing more than a million characters to be represented.
- Subsequent versions: gradual addition of historical characters, symbols, emojis, and new alphabets to meet the ever-growing needs of users.
How is Unicode organized?
Unicode is divided into 17 “planes,” each containing 65,536 code points (or unique character codes), for a total of more than a million possible positions. These planes are themselves grouped into blocks according to the type or origin of the characters.
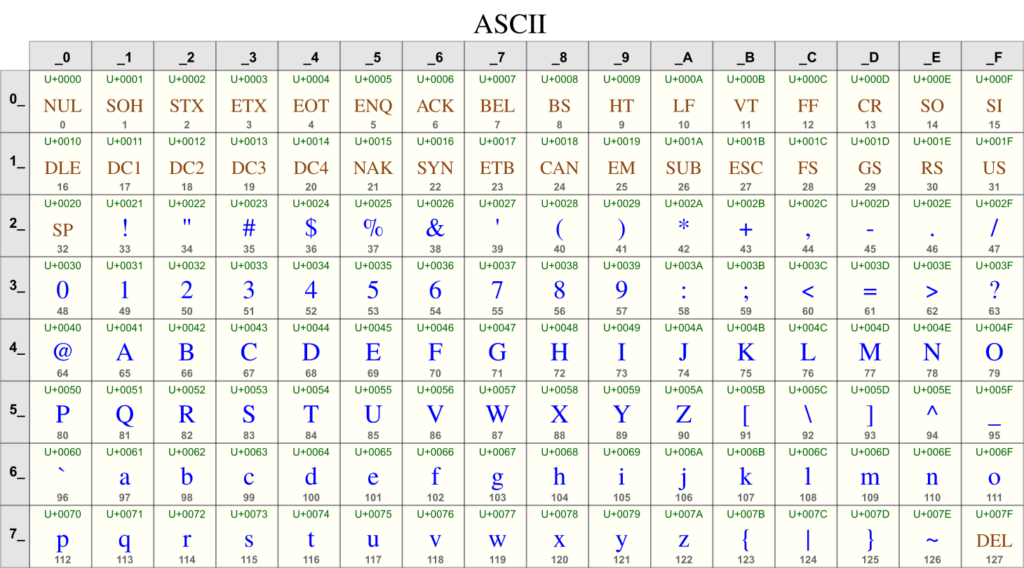
- Basic Multilingual Plane (BMP): This is the most important and widely used. It ranges from U+0000 to U+FFFF and contains the most common characters (Latin, Cyrillic, Arabic, Greek, Chinese, Japanese, Korean, etc.).
- Supplementary planes: Used for historical characters, rare languages, emojis, mathematical symbols, or private areas for companies or software that need custom characters.
Each character has a code point in the form U+XXXX (in hexadecimal). To store these characters, different encoding forms called UTF are used.
What are the different ways to use Unicode?
Example of Unicode conversion. Source: https://www.bytesroute.com/blog/unicode.html
The most well-known Unicode encodings are:
- UTF-8: This is the most widespread, especially on the Internet. It uses 1 to 4 bytes to encode a character. It has the advantage of being compatible with the old ASCII encoding, which makes migrations easier.
- UTF-16: Used especially by Windows, it encodes characters in 2 or 4 bytes. It is more efficient for Asian languages that use many characters.
- UTF-32: Here, each character uses 4 bytes. This is very simple for computers, but it takes up more memory.
Why is Unicode so important today?
Before Unicode, each language had its own encoding system, which caused many compatibility problems between software, websites, or documents. Unicode made it possible to unify all that.
Today, Unicode is absolutely essential for:
- Displaying texts in all languages on the same device or website.
- Sending emojis or special characters without errors.
- Programming applications that work worldwide.
Virtually all modern operating systems (Windows, macOS, Android, iOS), web browsers, and programming languages natively support Unicode.
What are the challenges of Unicode?
Unicode is very powerful, but it still faces several challenges:
- It is necessary to constantly add new characters, emojis, or ancient scripts.
- There are sometimes several ways to represent the same character (such as accents), which can cause problems when comparing texts.
- The management of some complex alphabets requires very technical display rules.
The Unicode Consortium continues to work to improve and evolve the standard according to the needs of the digital world.
In summary: what is Unicode for?
Unicode simply allows us to write, display, and transmit text universally, regardless of language or platform. Thanks to Unicode, we can read a tweet in Japanese, exchange emails with accents, program a multilingual website, or insert an emoji in a message.
Unicode is the common language of all digital texts.
Sources:
- https://en.wikipedia.org/wiki/Unicode
- https://home.unicode.org/
- https://unicode.org/faq/
- https://developer.mozilla.org/en-US/docs/Glossary/Unicode
- https://www.unicode.org/standard/WhatIsUnicode.html
- https://www.joelonsoftware.com/2003/10/08/the-absolute-minimum-every-software-developer-absolutely-positively-must-know-about-unicode-and-character-sets-no-excuses/